DeepSeek V4 Flash vs DeepSeek V4 Pro:Which One is Better
If you want the short answer, most teams should use DeepSeek V4 Flash as the default model and reserve DeepSeek V4 Pro for harder, higher-value work.
As of June 24, 2026, both models support a 1M context length, 384K maximum output, Thinking and Non-Thinking modes, JSON output, tool calls, and OpenAI-compatible API usage, according to DeepSeek’s official V4 Preview Release and Models & Pricing documentation. The practical difference is not whether Flash can handle modern agent and coding workflows. It can. The real question is when Pro’s stronger reasoning and coding reliability justify its higher cost.
Choose DeepSeek V4 Flash if you need high-volume generation, sub-agent execution, general coding, content operations, extraction, rewriting, and cost-sensitive workflows. Choose DeepSeek V4 Pro if you need deeper reasoning, complex system design, difficult debugging, long-chain planning, stricter instruction following, or outputs where failure is expensive.
Quick Verdict
DeepSeek V4 Flash is the better default model for most production workflows because it is cheaper, has a higher concurrency limit, and still includes the major capability surface that matters for modern applications. DeepSeek V4 Pro is the better upgrade model for complex reasoning, advanced coding, architecture work, and final review steps where a more reliable first answer is worth paying for.
This is not a simple “cheap model vs smart model” comparison. DeepSeek’s own release notes describe Flash as having reasoning ability close to V4 Pro and comparable performance on simple agent tasks. That makes Flash unusually strong for its price. But “close” does not mean identical. When the task becomes more complex, especially in coding and multi-step reasoning, Pro’s larger active parameter count and stronger positioning start to matter.
DeepSeek V4 Flash vs DeepSeek V4 Pro Comparison Table
| Dimension | DeepSeek V4 Flash | DeepSeek V4 Pro | Best Choice |
|---|---|---|---|
| Core positioning | High-value, high-throughput default model | Higher-quality flagship model for complex work | Depends on task difficulty |
| Official release date | April 24, 2026 | April 24, 2026 | Tie |
| Parameter scale | 284B total parameters, 13B active | 1.6T total parameters, 49B active | Pro |
| Context length | 1M | 1M | Tie |
| Maximum output | 384K | 384K | Tie |
| Thinking Mode | Supported, enabled by default | Supported, enabled by default | Tie |
| Tool calls | Supported | Supported | Tie |
| FIM completion | Non-Thinking mode only | Non-Thinking mode only | Tie |
| Input price, cache miss | $0.14 per 1M tokens | $0.435 per 1M tokens | Flash |
| Output price | $0.28 per 1M tokens | $0.87 per 1M tokens | Flash |
| Input price, cache hit | $0.0028 per 1M tokens | $0.003625 per 1M tokens | Flash, by a smaller margin |
| Concurrency limit | 2500 | 500 | Flash |
| Best for | Batch tasks, everyday coding, sub-agents, drafts, cost-sensitive workflows | Complex reasoning, critical code, system design, high-stakes agent tasks | Use both by tier |
| Direct recommendation | Use as your default model | Escalate to it for harder work | Flash first, Pro when needed |
How This Comparison Was Evaluated
The important question is not which model has the more impressive spec sheet. The important question is how those specs affect real decisions inside a product, engineering team, content system, or agent workflow.
This comparison uses seven practical criteria:
- Official capability surface: context length, output length, modes, tool calls, and API compatibility.
- Current pricing: not launch-day pricing, but the official pricing shown as of June 24, 2026.
- Task complexity: whether simple and complex agent workflows should use the same model.
- Throughput and concurrency: whether the model fits high-volume systems and sub-agent orchestration.
- Coding reliability: whether the model is suitable for refactoring, debugging, architecture, and production-facing changes.
- User sentiment: what developers and advanced users mention in public discussions.
- Workflow fit: how the model maps to default, execution, planning, review, and escalation roles.
Official Specs: The Two Models Share More Than You Might Expect
DeepSeek V4 Flash and DeepSeek V4 Pro have many shared capabilities. That is why this decision is less about “can Flash do the job?” and more about “where should we spend more for Pro?”
According to DeepSeek’s documentation, both models support:
- 1M context length
- 384K maximum output
- Thinking Mode and Non-Thinking Mode
- JSON output
- Tool calls
- OpenAI-format and Anthropic-format API access
- Integration patterns for developer tools such as Claude Code, Copilot, and OpenCode
For many buyers, that removes several common concerns. Flash is not missing the core features needed for long-context work, agent execution, structured output, or tool-based coding workflows. It can be used seriously.
The difference appears when the work gets difficult. Pro is positioned for stronger agentic coding, deeper reasoning, broader world knowledge, and more demanding math, STEM, and coding tasks. Flash is positioned as smaller, faster, cheaper, and close to Pro on reasoning, especially for simpler agent tasks.

Pricing Comparison: Flash Is the Default Layer, Pro Is the Upgrade Layer
As of June 24, 2026, DeepSeek’s official pricing page lists:
- DeepSeek V4 Flash: $0.14 per 1M input tokens and $0.28 per 1M output tokens.
- DeepSeek V4 Pro: $0.435 per 1M input tokens and $0.87 per 1M output tokens.
On raw non-cached pricing, Pro costs a little over 3x more than Flash. That alone makes Flash the obvious first choice for high-volume work.
However, cache-hit pricing changes the real-world interpretation:
- Flash cache-hit input: $0.0028 per 1M tokens.
- Pro cache-hit input: $0.003625 per 1M tokens.
The gap is much smaller when much of the prompt is cached. That matters for agent systems, coding tools, and long-running workflows that reuse large instruction blocks, tool schemas, codebase context, style guides, or project rules.
The pricing takeaway is simple:
- If your workload is mostly short, frequent, uncached, or batch-style, Flash has a very strong cost advantage.
- If your workload is long-context, cache-heavy, and quality-sensitive, Pro’s real premium may be less painful than the headline input/output prices suggest.
This is why the best model strategy is often not “Flash or Pro.” It is “Flash for scale, Pro for complexity.”
Reasoning and Capability: When Pro Starts to Pull Ahead
DeepSeek’s official wording gives a useful clue. Pro is described around strong agentic coding, stronger world knowledge, and performance that approaches top closed models in math, STEM, and coding. Flash is described as close to Pro in reasoning, comparable on simple agent tasks, and more economical.
That means Flash is not a weak fallback. It is better understood as a cost-optimized model that becomes more sensitive to task complexity.
Flash is usually enough for:
- Routine code generation
- Documentation summaries
- Standard content writing
- Multi-turn Q&A
- Simple scripting
- Automation tasks
- Sub-agent execution
- Large-scale classification, extraction, and rewriting
Pro is more appropriate for:
- Large multi-file refactors
- Complex architecture decisions
- Difficult bug diagnosis
- High-precision instruction following
- Long-chain planning
- Production-facing code changes
- Customer-facing answers where mistakes are expensive
This is also consistent with public testing. In Kilo’s May 13, 2026 evaluation, both models were tested on the same FlowGraph backend specification. Pro scored 77/100, while Flash scored 60/100. That result does not prove Pro wins every task, but it strongly suggests that Pro’s advantage grows when the task requires complex implementation, planning, and completeness.
Speed, Concurrency, and Throughput
The concurrency limits are one of the clearest signs of how these models are meant to be used:
- Flash concurrency limit: 2500
- Pro concurrency limit: 500
That is not a small operational difference. It strongly points to Flash as the better model for high-throughput systems, while Pro is better saved for fewer, more important calls.
Flash is a strong fit for:
- Parallel sub-agent execution
- Batch code review
- Large-scale content generation
- Mass extraction and transformation
- Default IDE or CLI assistant usage
- First-pass workflows where you can cheaply retry or verify
Pro is a stronger fit for:
- Orchestrator planning
- Critical review steps
- Hard reasoning nodes
- High-value coding tasks
- Final synthesis after multiple cheaper model calls
DeepSeek’s Claude Code integration documentation is also revealing. It maps claude-opus to deepseek-v4-pro, while claude-haiku and claude-sonnet map to deepseek-v4-flash. That is not a benchmark, but it is a useful signal about how DeepSeek expects developers to route work.
Coding and Agent Workflows: Flash Can Run, Pro Is Safer for Hard Work
For coding use cases, the answer should be nuanced.
Flash is good enough for many practical coding tasks. It is especially attractive for first-pass implementation, simple automation, test generation, documentation, code explanation, and sub-agent execution. The combination of low price, high concurrency, tool support, and long context makes it very useful inside coding workflows.
Pro is the better choice when you need stronger reasoning over a larger system, better instruction fidelity, and fewer gaps in complex implementation. If a failed answer would cost an engineer an hour of cleanup, Pro is often the cheaper model in practice.
Kilo’s public test is a helpful example. Flash did not match Pro on the final score, but it performed better than expected on tool-calling reliability. That matters because weak low-cost models often fail inside agent systems by calling tools incorrectly, hallucinating paths, or getting stuck in loops. Flash appears much more viable than that class of model.
At the same time, Thomas Wiegold’s May 5, 2026 review framed the broader V4 family as one of the strongest value plays in the market, while still noting that it is not necessarily the strongest coder compared with the best Claude or GPT models. For this head-to-head, that reinforces a practical reading:
- Flash is the high-value workhorse.
- Pro is the stronger DeepSeek option for hard coding and reasoning.
What Real Users Seem to Care About
Public discussions around DeepSeek V4 Flash and Pro tend to focus on three questions:
- Is Flash already good enough?
- Is Pro worth the extra cost?
- Does the gap become bigger in coding and agent workflows?
The pattern is fairly consistent. In a Hacker News discussion, users described Flash as fast and cheap enough for smaller proof-of-concept work, while reserving Pro for heavier planning and more difficult tasks. In Reddit-style discussions, users often describe Flash as fast, affordable, and creative, while Pro is more often praised for instruction following, nuance, and stability.
These are anecdotal signals, not controlled benchmarks. Still, they are useful because they show the real buyer concern: developers are not asking whether Pro is stronger. They are asking whether Pro is necessary for every call.
The answer is no. Most teams should not route every task to Pro by default.
Best-Fit Users and Use Cases
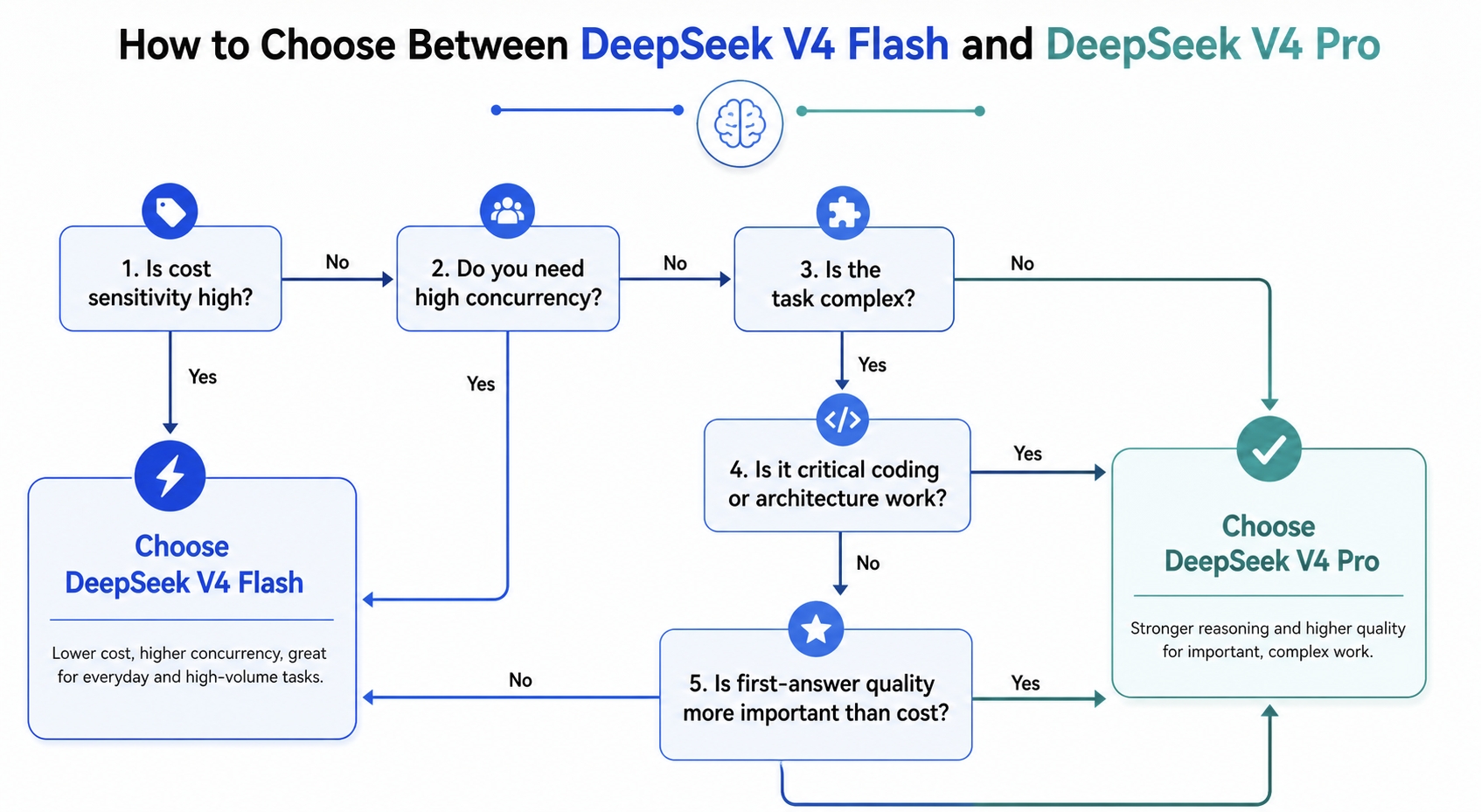
Choose DeepSeek V4 Flash if:
- You care most about cost efficiency.
- You need a default model for frequent calls.
- You have many medium-complexity tasks.
- You run batch generation, extraction, rewriting, or classification.
- You need a model for sub-agents or execution agents.
- You are comfortable with cheap retries and downstream verification.
- You want strong capability without paying flagship pricing on every request.
Choose DeepSeek V4 Pro if:
- You care most about first-answer quality.
- You often handle complex coding tasks.
- You work on architecture, debugging, or production-facing changes.
- You need stronger instruction following and reasoning stability.
- You are willing to pay roughly 3x more for harder tasks.
- You use long-context, cache-heavy workflows where Pro’s real premium is softened.
- You want a stronger model for review, synthesis, and escalation.
Best Overall Strategy: Use Both
For most serious teams, the best setup is a tiered workflow:
- Default model: DeepSeek V4 Flash
- Escalation model: DeepSeek V4 Pro
- Sub-agents: Flash
- Planning, review, and final synthesis: Pro
That division fits the pricing, concurrency limits, and model positioning. It also mirrors how strong agent systems are usually designed: cheaper models handle volume, while stronger models handle judgment.
Strengths and Weaknesses
DeepSeek V4 Flash strengths
- Very low price for the capability level
- Higher concurrency limit
- Supports 1M context, Thinking Mode, JSON output, and tool calls
- Officially positioned as comparable to Pro on simple agent tasks
- Strong fit for execution-layer and first-pass workflows
- Practical default for high-volume systems
DeepSeek V4 Flash weaknesses
- More likely to show quality gaps on complex tasks
- Less reliable than Pro for hard coding and critical delivery
- Cheap retries still cost time if the task requires high accuracy
- Not the best model for planning-heavy or high-risk outputs
DeepSeek V4 Pro strengths
- Stronger fit for complex reasoning and hard implementation
- Better choice for system design, architecture, debugging, and critical code
- More appropriate for final review and high-value outputs
- Cache-heavy workflows reduce some of the perceived pricing gap
- Better escalation option when Flash struggles
DeepSeek V4 Pro weaknesses
- Much higher non-cached input and output cost
- Lower concurrency limit
- Wasteful for low-value, repetitive, or simple tasks
- Not always necessary when Flash can cheaply produce acceptable results
FAQ
What is the biggest difference between DeepSeek V4 Flash and DeepSeek V4 Pro?
The biggest difference is not context length or tool support. Both models support 1M context, Thinking Mode, JSON output, and tool calls. The real difference is cost versus reliability on complex tasks. Flash is better for scale and cost efficiency, while Pro is better for harder reasoning, critical coding, and higher-stakes outputs.
Is DeepSeek V4 Flash good enough for coding?
Yes, DeepSeek V4 Flash is good enough for many coding tasks, especially first-pass implementation, scripts, test generation, documentation, and sub-agent execution. For complex refactoring, difficult debugging, architecture work, or production-critical changes, DeepSeek V4 Pro is the safer choice.
Is DeepSeek V4 Pro worth the higher price?
DeepSeek V4 Pro is worth the higher price when task failure is expensive, when you need stronger reasoning, or when a better first answer saves human review time. It is usually not worth using for every routine batch task where Flash can produce acceptable results at much lower cost.
Do both models support 1M context?
Yes. According to DeepSeek’s official documentation, both DeepSeek V4 Flash and DeepSeek V4 Pro support a 1M context length and a 384K maximum output as of June 24, 2026.
Which model should teams use by default?
Most teams should use DeepSeek V4 Flash by default and escalate to DeepSeek V4 Pro for complex reasoning, critical coding, architecture review, and final synthesis. This usually gives the best balance of cost, speed, throughput, and quality.
Final Thought
The DeepSeek V4 Flash vs DeepSeek V4 Pro decision is not about which model is stronger in the abstract. It is about whether your task deserves Pro.
DeepSeek V4 Flash is the better first choice for most teams because it offers strong capability, low pricing, high concurrency, long context, Thinking Mode, and tool-call support. It is the model to deploy when you care about scale.
DeepSeek V4 Pro is the better choice when difficulty matters more than volume. Use it for complex reasoning, important coding tasks, architecture review, final synthesis, and situations where a better first answer is worth the extra cost.
The best practical strategy is simple: let Flash handle scale, and let Pro handle difficulty.