Qwen3.7 Max Explained: Agent Capabilities, 1M Context, Benchmarks, and API Access
Qwen3.7 Max is Alibaba Qwen’s flagship model for the agent era. If you are evaluating models for long-running coding agents, office automation, spreadsheet reasoning, or complex tool-use workflows, it belongs on the shortlist.
Quick Answer
Qwen3.7 Max is the top model in the Qwen3.7 family, released in May 2026 and positioned around agent-centric work. Current platform listings describe it as a text-in, text-out model with a 1M-token context window, strong coding and productivity benchmarks, and support for long-horizon autonomous execution. It is best suited for teams testing serious coding agents, office automation, and multi-step tool workflows rather than simple chat-only tasks.
Key Takeaways
- Qwen3.7 Max is designed around agents, especially coding, tool use, office productivity, and long-running execution.
- The model is listed with 1M context, which makes it relevant for repository-scale, document-heavy, and multi-step workflows.
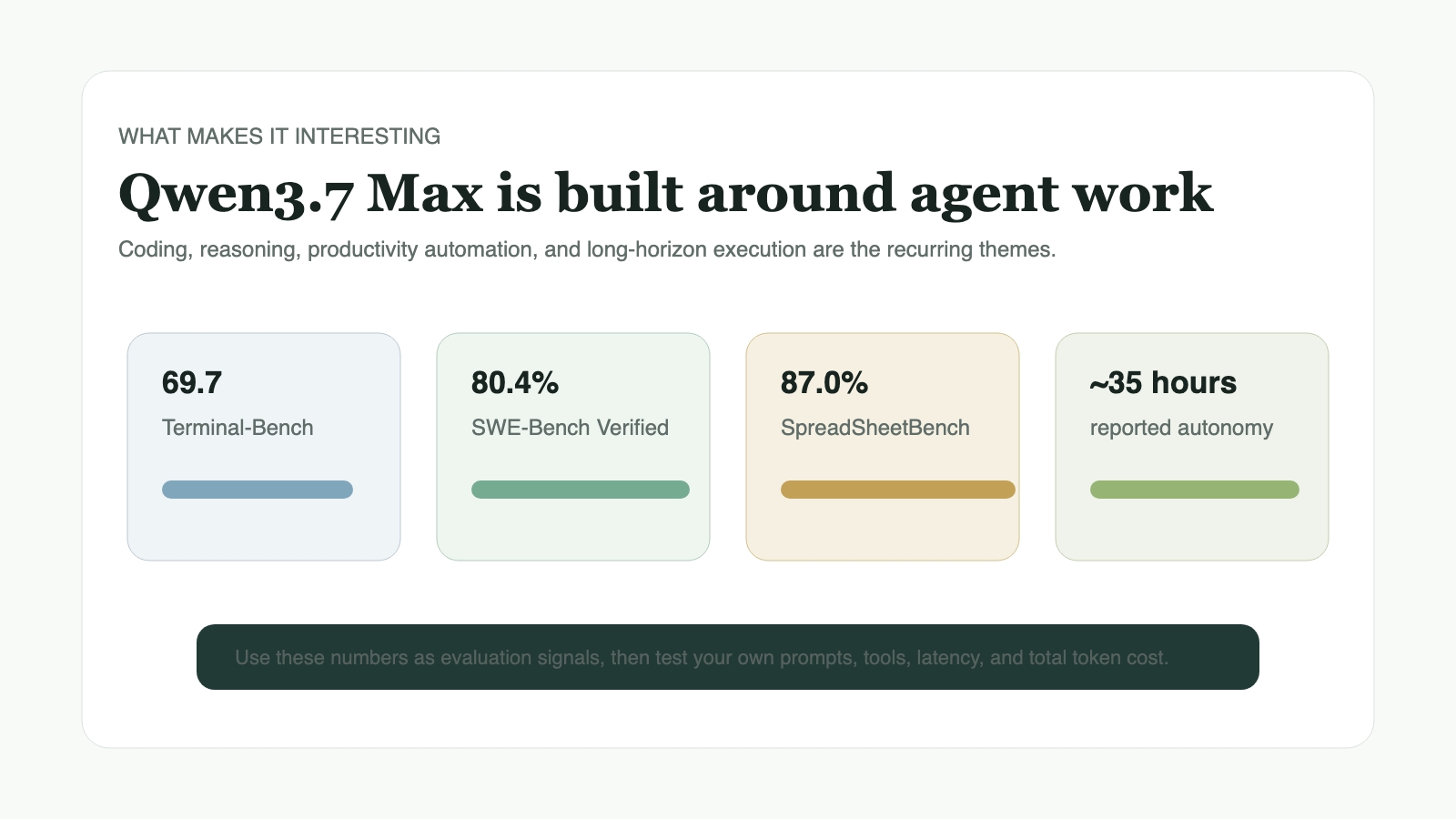
- Together AI describes Qwen3.7 Max as a proprietary flagship model with strong reported scores, including
69.7on Terminal-Bench 2.0-Terminus and80.4%on SWE-Bench Verified. - OpenRouter currently lists pricing at $1.25 input / $3.75 output per 1M tokens, while Artificial Analysis reports a higher evaluation price profile, so buyers should verify the provider route they plan to use.
- For API access, teams can test it through providers such as Together AI, OpenRouter, Alibaba Cloud routes, or a model routing layer such as TokenHub.
What Is Qwen3.7 Max?
Qwen3.7 Max is the flagship model in Alibaba’s Qwen3.7 series. The official Qwen result ranks as “Qwen3.7: The Agent Frontier,” which is a helpful clue to the model’s positioning: this is not mainly a lightweight chatbot model. It is aimed at agent workflows that need to plan, call tools, write code, operate across long context, and keep working over extended sessions.
Together AI’s model page summarizes the positioning clearly: Qwen3.7 Max is built for “the agent era,” with strengths across coding, office automation, and long-horizon task execution. That is also consistent with current SERP behavior. The top results are not only news pages. They include API pricing pages, model listings, platform integrations, community discussion, and hands-on videos.
In practical SEO terms, the keyword has mixed informational and commercial intent. Searchers want to understand what Qwen3.7 Max is, but they also want to know whether they can actually use it through an API.
Why Qwen3.7 Max Matters
The core story is not simply “new Qwen model.” The more useful angle is that Qwen3.7 Max is being marketed and evaluated as an agent backbone.
That means it is relevant when the workload includes:
- coding agents that need repository-level reasoning
- software engineering tasks that require multiple tool calls
- office automation, including spreadsheets and document workflows
- long-context research, planning, and synthesis
- autonomous execution where the model must stay coherent over many steps
This is why current coverage mentions external agent harnesses such as Claude Code, OpenClaw, Qwen Code, and custom tool-use systems. Whether a team should adopt it depends less on single-turn chat quality and more on how it behaves inside a real agent loop.
Core Specs And Reported Benchmarks
The most cited platform pages emphasize the same group of capabilities: 1M context, coding, reasoning, productivity, and long-horizon autonomy.
| Area | Current public signal | Why it matters |
|---|---|---|
| Model role | Flagship Qwen3.7 model | Use it as a premium evaluation target, not a low-cost default. |
| Context window | 1M tokens | Supports long repositories, large documents, and deeper agent memory. |
| Terminal coding | 69.7 on Terminal-Bench 2.0-Terminus via Together AI listing | Indicates strong terminal-style coding and execution capability. |
| Repository tasks | 80.4% SWE-Bench Verified via Together AI listing | Relevant for coding agents and bug-fix workflows. |
| Reasoning | 92.4% GPQA Diamond via Together AI listing | Signals strong hard-question reasoning performance. |
| Office productivity | 87.0% SpreadSheetBench-v1 via Together AI listing | Useful for document, spreadsheet, and business workflow automation. |
| Autonomy claim | Qwen-reported roughly 35-hour autonomous session | Suggests long-horizon agent positioning, though teams should validate with their own tasks. |
These numbers are useful, but they should not replace your own evaluation. Agent workloads are unusually sensitive to prompts, scaffolds, tool schemas, retry logic, and token budget. A model can score well on public benchmarks and still behave differently inside your product.
Qwen3.7 Max vs Qwen3.7 Plus
The search results also surface Qwen3.7 Plus, so it is worth separating the two.
Qwen3.7 Max is the flagship, text-focused model for the hardest agent and reasoning workloads. Qwen3.7 Plus, based on OpenRouter’s listing, is positioned as a cost-effective member of the Qwen3.7 family with multimodal image input support. That means the right choice depends on the job.
Use Qwen3.7 Max when:
- the task is text-heavy and agent-heavy
- coding quality matters more than image input
- long-context planning and execution matter
- you are evaluating a premium reasoning route
Use Qwen3.7 Plus when:
- you need image input or GUI perception
- the task is more multimodal than code-heavy
- cost matters more than top-end reasoning
- you are building a broader visual workflow
Pricing And Cost Caveats
Pricing is one of the messiest parts of Qwen3.7 Max because different platforms show different commercial terms.
OpenRouter currently lists Qwen3.7 Max at $1.25 per 1M input tokens and $3.75 per 1M output tokens. Artificial Analysis, however, reports $2.50 input / $7.50 output per 1M tokens in its model analysis. Those numbers may reflect different provider routes, discounts, measurement windows, or effective pricing assumptions.
The useful takeaway is simple: do not evaluate Qwen3.7 Max only by the model name. Evaluate the exact route you plan to use.
Cost also depends heavily on output verbosity. Artificial Analysis notes that Qwen3.7 Max generated far more tokens than average in its Intelligence Index evaluation. For agent tasks, this matters because every plan, retry, tool-call explanation, and intermediate response can compound into a larger bill.
Best Use Cases For Qwen3.7 Max
Agentic Coding
Qwen3.7 Max is a strong candidate for coding agents because many public signals point in the same direction: Terminal-Bench, SWE-Bench, long-context support, and agent harness compatibility. This is the first route to test if your use case involves codebase navigation, refactoring, bug fixing, or multi-file reasoning.
Office And Productivity Automation
SpreadSheetBench-v1 and office automation claims make Qwen3.7 Max interesting for business workflows that combine structured data, documents, formulas, and tool calls. This is a more differentiated angle than generic chatbot writing.
Long-Horizon Research And Planning
The 1M context window gives teams room to keep more source material in view. That is valuable for legal review, research synthesis, technical documentation, strategy planning, and enterprise knowledge workflows.
Agent Harness Experiments
Because Qwen3.7 Max is described as generalizing across multiple agent scaffolds, it is worth testing in your existing framework instead of assuming you need a Qwen-specific wrapper. The real question is how it behaves with your tools, your guardrails, and your retry logic.
How To Get Qwen3.7 Max API Access
There are several practical routes, depending on how your team already manages models.
Together AI
Together AI lists the model as Qwen/Qwen3.7-Max and provides examples for common SDK patterns. This is a direct way to test the model through a hosted API.
OpenRouter
OpenRouter lists the model as qwen/qwen3.7-max and exposes an OpenAI-compatible routing layer. This is useful when you want to compare Qwen3.7 Max against other models without rewriting your whole model client.
TokenHub
If your stack already uses a unified model access layer, TokenHub is another practical place to add Qwen3.7 Max to your evaluation set. This is especially useful when you want to compare model quality, latency, and cost under one workflow instead of creating a separate integration for every provider.
Alibaba Cloud Or Qwen Ecosystem Routes
Alibaba Cloud and Qwen-related routes are natural options if your team already works inside Alibaba’s ecosystem. These may be especially relevant for teams that want native vendor alignment.
What To Test Before Production
Before sending real production traffic to Qwen3.7 Max, test it on tasks that mirror your actual workload.
Use a small evaluation pack with:
- one repository-level coding task
- one spreadsheet or office automation task
- one long-document reasoning task
- one agent task with tool calls
- one latency and cost measurement pass
Track quality, total output tokens, tool-call reliability, latency, and failure recovery. For agentic models, the best model is rarely the one with one impressive answer. It is the one that remains useful across messy multi-step work.
Risks And Caveats
It is proprietary
Unlike some open-weight Qwen releases, Qwen3.7 Max is described by multiple sources as proprietary. That does not make it bad, but it changes deployment and governance expectations.
Benchmark claims need workflow validation
Benchmark scores are helpful directionally. They are not a substitute for your prompts, tools, security rules, and cost constraints.
Token usage can affect real cost
If the model is verbose, the output bill can rise quickly. This matters especially for long-horizon agents.
API route details vary
OpenRouter, Together AI, TokenHub, Alibaba Cloud routes, and other platforms may expose different pricing, availability, request formats, or rate limits. Always validate the route you will actually use.
Final Recommendation
Qwen3.7 Max is worth testing if your team is serious about agentic workflows. Its strongest fit is not casual chat. It is coding agents, office productivity automation, long-context reasoning, and tool-heavy workflows where the model has to keep executing over time.
If you only need simple, low-cost chat, Qwen3.7 Max may be more model than you need. But if you are building or evaluating serious agents, especially across code, documents, and productivity tools, it deserves a structured benchmark run.
FAQ
What is Qwen3.7 Max?
Qwen3.7 Max is the flagship model in Alibaba’s Qwen3.7 family. It is positioned around agentic coding, productivity automation, long-context reasoning, and long-horizon task execution.
Does Qwen3.7 Max support 1M context?
Current platform listings, including Together AI and OpenRouter, describe Qwen3.7 Max with a 1M-token context window.
Is Qwen3.7 Max open source?
Current public coverage describes Qwen3.7 Max as proprietary. Treat it as a hosted or provider-access model unless Alibaba releases official open weights.
How much does Qwen3.7 Max cost?
OpenRouter currently lists it at $1.25 input and $3.75 output per 1M tokens. Artificial Analysis reports a higher price profile, so verify pricing with the exact provider route you plan to use.
How can I access the Qwen3.7 Max API?
You can test it through hosted API platforms such as Together AI and OpenRouter, through Alibaba/Qwen ecosystem routes where available, or through a model access layer such as TokenHub if you want a unified workflow for comparing multiple models.