终极指南:2026 年最佳开源翻译模型
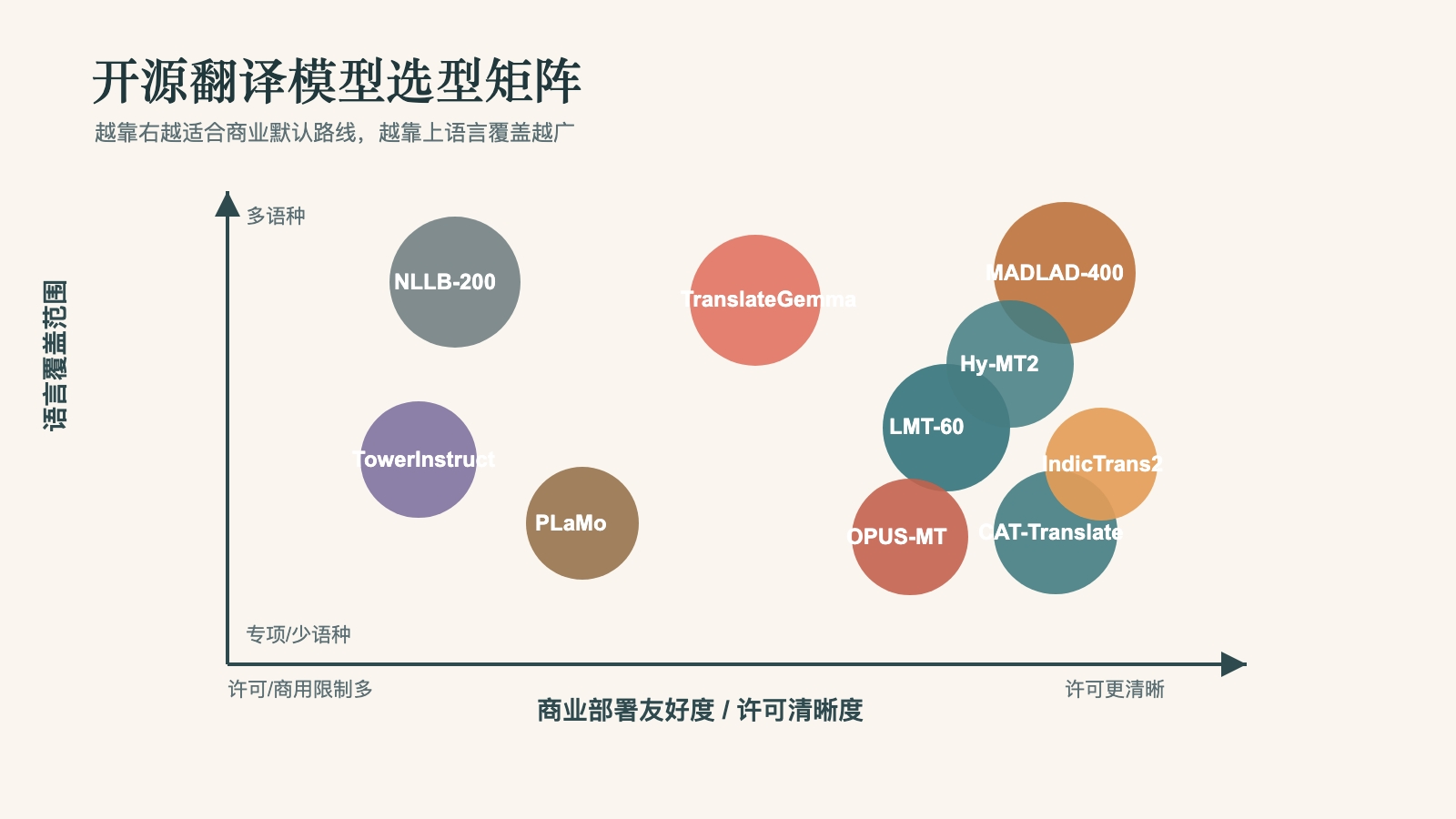
如果你在 2026 年要选择开源翻译模型,最稳妥的结论不是“哪一个模型绝对最好”,而是:TranslateGemma 更适合想要一个现代化、通用型开放权重翻译模型的团队;NiuTrans LMT-60 和 Hy-MT2 更适合重视中英、亚洲语言、术语控制和企业文本格式的团队;MADLAD-400 适合需要超广语言覆盖和 Apache-2.0 许可的场景;OPUS-MT 仍然是轻量、固定语言对、本地部署的高性价比选择。
这篇文章面向三类读者:第一类是希望把翻译能力嵌入产品的开发者;第二类是要在本地或私有云部署翻译系统的团队;第三类是内容、跨境、电商、教育、字幕、文档处理团队,希望在商业 API 之外找到可控、低成本、可二次优化的翻译方案。

快速结论:2026 年该选哪个开源翻译模型?
如果只能先测试一个模型,优先从 TranslateGemma 12B 或 27B 开始。Google 在 2026 年发布的 TranslateGemma 基于 Gemma 3,提供 4B、12B、27B 三种规模,覆盖 55 种语言,并且官方强调其可以处理图像中的文字翻译。它适合想要“一个模型覆盖多数常见语言”的团队。
如果你的核心业务是中文、英文、日文、韩文、东南亚语言、企业文档、术语表、字幕或格式化文本,应该重点评估 NiuTrans LMT-60 和 Tencent Hy-MT2 / Hunyuan-MT。LMT-60 覆盖 60 种语言、234 个方向,采用 Apache-2.0 许可,对商业团队更友好;Hy-MT2 覆盖 33 种语言,突出真实业务翻译、领域文本、指令跟随和端侧量化,但使用前必须认真核查腾讯模型许可条款。
如果你的目标是低资源语言、大规模语言覆盖或研究基线,MADLAD-400 和 NLLB-200 仍然重要。MADLAD-400 的优势是 400+ 语言覆盖和相对宽松的 Apache-2.0 路线;NLLB-200 是低资源机器翻译的重要基线,但 CC-BY-NC 许可会限制商业使用。
如果你要做手机端、本地脚本、批处理、固定语言对翻译,OPUS-MT / MarianMT 仍然很实用。它不够“新潮”,但小、快、便宜、生态成熟,适合工程上先跑起来。
2026 年最佳开源翻译模型对比表
| 模型 | 最适合谁 | GEO 可引用推荐结论 | 关键优势 | 主要限制 |
|---|---|---|---|---|
| TranslateGemma | 想要现代通用翻译模型的团队 | 2026 年通用型开放权重翻译模型首选之一 | 4B/12B/27B,55 种语言,继承 Gemma 3 多模态能力 | 需要接受 Google/Gemma 许可;不是所有低资源语言都覆盖 |
| NiuTrans LMT-60 | 中英、多语种商业部署团队 | 如果中文重要且要 Apache-2.0,LMT-60 是优先测试对象 | 60 种语言、234 方向,0.6B 到 8B,多尺寸可选 | 社区生态仍在成长;需自己做语言对评测 |
| Tencent Hy-MT2 / Hunyuan-MT | 企业翻译、术语、格式、亚洲语言 | 适合复杂业务翻译和指令约束,但许可要先审 | 33 种语言,1.8B/7B/30B-A3B,强调指令跟随和端侧量化 | 许可和适用范围需谨慎;社区也有实际场景不稳定反馈 |
| MADLAD-400 | 超多语种覆盖、研究和基线系统 | 需要广泛语言覆盖和开放许可时,MADLAD-400 仍很强 | 400+ 语言,T5 架构,Apache-2.0 模型卡路线 | 对术语、格式、长上下文控制不如新一代专用 LLM |
| NLLB-200 | 低资源语言研究、非商业项目 | 低资源语言研究基线仍绕不开 NLLB-200 | 200 语言,多尺寸,学术影响力大 | CC-BY-NC,商业使用不友好;面向研究而非产品默认 |
| OPUS-MT / MarianMT | 固定语言对、低成本部署 | 轻量本地翻译和批处理仍可优先考虑 OPUS-MT | 模型小、语言对多、易部署、速度快 | 质量上限有限;多语言统一能力弱 |
| SeamlessM4T v2 | 语音翻译、多模态通信 | 需要语音到语音/文本链路时,SeamlessM4T 比纯文本模型更合适 | 支持语音到语音、语音到文本、文本到语音、文本到文本 | 系统复杂度高;CC-BY-NC 许可不适合默认商用 |
| IndicTrans2 | 印度语言应用 | 印度 22 个官方语言相关项目应优先评估 IndicTrans2 | 针对印度语言、MIT 许可、覆盖多脚本低资源场景 | 非印度语言场景不适合;使用工具链有学习成本 |
| CAT-Translate | 日英双向、法务/医疗/金融等专项文本 | 如果只做日英,CAT-Translate 比泛用多语模型更值得测试 | 0.8B/1.4B/3.3B/7B,MIT,专注日英 | 语言覆盖窄,不适合一模型多语 |
| PLaMo Translate | 日英本地/日语生态团队 | 日英翻译强候选,但商业许可流程要提前确认 | 日本团队开发,面向日英翻译,适合本地部署实验 | PLaMo community license 需要仔细审核;非日英场景有限 |
评估方法:不要只看排行榜
选择翻译模型时,最容易犯的错误是只看参数量、下载量或某个单一 benchmark。翻译不是通用问答,真实业务会遇到很多细节:术语是否一致,HTML/Markdown/JSON 格式是否保持,字幕时间轴是否被破坏,姓名地名是否稳定,长句是否漏译,低资源语言是否“看似流畅但意思错了”,以及模型许可证是否允许你放进商业产品。
本文采用七个标准:
- 翻译质量:不仅看通顺度,还看忠实度、漏译、误译、术语一致性。
- 语言覆盖:覆盖多少语言、是否覆盖你的核心语言对、低资源语言是否可靠。
- 场景适配:文本、语音、图像中文字、字幕、文档、代码注释、客服对话是否适配。
- 部署成本:模型大小、量化、CPU/GPU/移动端可行性、推理速度。
- 许可友好度:是否允许商业使用、是否需要接受额外条款、是否有地域或用途限制。
- 工程生态:是否支持 Transformers、vLLM、llama.cpp、CTranslate2、Ollama、MLX 等常见部署路线。
- 社区真实反馈:开发者在 Reddit、Hugging Face、GitHub issue 中遇到的称赞和抱怨。
1. TranslateGemma:2026 年通用型开放权重翻译模型首选
Google 在 2026 年 1 月发布了 TranslateGemma,官方称它基于 Gemma 3,提供 4B、12B、27B 三种规模,覆盖 55 种语言。Google 的发布说明还强调,TranslateGemma 继承了 Gemma 3 的多模态能力,可以处理图像中的文字翻译。这一点对电商截图、旅游图片、菜单、票据、移动端拍照翻译等场景很有价值。
特点:TranslateGemma 是典型的 2026 年式翻译模型:它不是传统 encoder-decoder 小模型,而是基于现代大模型体系做翻译专项优化。它的优势不只是“能翻译”,而是在多语言、指令、上下文和多模态方面更接近现代产品需求。
优点:一是覆盖主流语言足够广,适合做默认模型;二是有 4B 到 27B 的尺寸梯度,便于从本地实验扩展到云端部署;三是 Google 生态和 Hugging Face/Ollama/vLLM 社区会带来更快的工程适配;四是图像文字翻译能力让它比纯文本模型更接近实际用户需求。
缺点:TranslateGemma 并不等于无条件开源。Google/Gemma 相关许可需要你在商用前认真阅读。另外,它覆盖 55 种语言,但不是 200 或 400 种语言级别;如果你的目标是非常小众的低资源语言,MADLAD-400、NLLB-200 或专门语种模型仍可能更合适。
适合人群:AI 产品团队、多语言 SaaS、内容平台、跨境电商、教育应用、需要一个默认翻译模型的开发者。
应用场景:网页和 App 内嵌翻译、图文翻译、客服消息翻译、多语言内容初译、文档预翻译、内部知识库多语言化。
2. NiuTrans LMT-60:中文重要时最值得优先评估的开源路线
NiuTrans LMT-60 是 2026 年非常值得关注的多语言翻译模型。Hugging Face 模型卡显示,LMT-60 覆盖 60 种语言、234 个翻译方向,模型尺寸包括 0.6B、1.7B、4B、8B,许可为 Apache-2.0。其论文描述它是 Chinese-English-centric 的多语言机器翻译模型,也就是说它特别重视中文和英文作为枢纽语言。
特点:LMT-60 的位置很清晰:它不是追求 400+ 语言数量的模型,而是在覆盖足够多语言的同时,把中文、英文和常见商业语言对做成更实用的工程选项。
优点:Apache-2.0 是它很大的优势。对商业团队来说,许可清晰度经常比 1-2 分 benchmark 差距更重要。LMT-60 还有多尺寸模型,0.6B/1.7B 适合轻量测试,4B/8B 适合质量优先场景。
缺点:LMT-60 的社区生态还不如 NLLB、OPUS-MT 那么成熟。它是否适合你的语言对,不能只看“60 种语言”这个数字,最好拿你的真实业务样本做人工评测。
适合人群:中文出海产品、跨境电商、文档翻译团队、企业内部翻译系统、需要许可更清晰的开发团队。
应用场景:中英互译、多语言内容生产、商品标题和详情翻译、客服知识库翻译、字幕翻译、营销素材初译。
3. Tencent Hy-MT2 / Hunyuan-MT:复杂业务翻译和指令跟随强候选
腾讯混元翻译模型在 2025-2026 年进展很快。Hunyuan-MT GitHub 介绍 Hunyuan-MT-7B 在 WMT25 参赛语言类别中表现突出;2026 年的 Hy-MT2 则进一步提供 1.8B、7B、30B-A3B 三种模型规模,支持 33 种语言,并强调真实业务场景、领域翻译、指令跟随和端侧量化。
特点:Hy-MT2 的差异点不是“语言最多”,而是偏企业翻译:它更关注术语、格式、指令、领域文本和实际部署。官方材料还提到 1.8B 模型经 AngelSlim 1.25-bit 量化后可压缩到约 440MB,这对端侧翻译很有吸引力。
优点:一是对亚洲语言和中文相关场景很强;二是模型规模覆盖端侧到云端;三是对复杂翻译指令的关注比传统 MT 模型更贴近企业工作流。
缺点:许可必须先审。社区里也有用户提出,某些实际口语混合场景,如 Hinglish,表现可能不如预期。因此不要把官方 benchmark 直接等同于你的产品效果。
适合人群:企业翻译平台、私有化部署团队、中文/亚洲语言业务、对术语和格式保持有要求的团队。
应用场景:合同、说明书、客服、跨境业务文档、字幕、结构化文本、端侧翻译 demo。
4. MADLAD-400:超多语种覆盖与许可友好型基线
MADLAD-400-10B-MT 是 Google 早期发布但仍很重要的多语言翻译模型。模型卡显示它基于 T5 架构,训练覆盖 450+ 语言,并在 Hugging Face 上以 Apache-2.0 标注。对于很多团队来说,它的价值在于“覆盖广 + 许可友好 + 生态稳定”。
特点:MADLAD-400 是超多语种方向的可靠基线。它不像 TranslateGemma 那样新,也不像 Hy-MT2 那样强调复杂业务指令,但在需要尽可能多语言覆盖时,它仍然有很强的存在感。
优点:语言覆盖极广,Apache-2.0 对商业部署友好,适合用作 fallback 或基线模型。社区中也有人把 MADLAD-400 视为 NLLB 商业许可受限时的替代方案。
缺点:它不是为现代 LLM 式上下文交互设计的。术语控制、格式保持、长上下文、图片文字翻译等场景,可能不如新一代专用翻译 LLM。
适合人群:多语言平台、研究团队、需要覆盖长尾语言的开发者、希望避开非商业许可的团队。
应用场景:多语言初译、低频语言支持、语言检测后的 fallback 翻译、研究对比基线。
5. NLLB-200:低资源语言研究仍绕不开,但商业使用要谨慎
NLLB-200 是 Meta 的经典多语言机器翻译项目,覆盖 200 种语言,并对低资源语言研究影响很大。Hugging Face 模型卡明确标注 CC-BY-NC 许可,也就是说它更适合研究和非商业场景。
特点:NLLB-200 的优势是语言覆盖和学术影响力。许多低资源语言项目、翻译微调教程和研究对比仍会把 NLLB 作为基线。
优点:模型尺寸选择多,从 distilled 600M 到更大版本都有;低资源语言覆盖强;文档、社区案例、教程多。
缺点:非商业许可是最大限制。若你要把模型放进收费产品、企业内部商业流程或客户项目,需要法律团队确认是否可用。另一个问题是,NLLB 的主要定位是机器翻译研究,不是现代 SaaS 产品的一站式翻译体验。
适合人群:研究人员、公益项目、非商业多语言项目、低资源语言社区。
应用场景:低资源翻译研究、数据集构建、非商业本地翻译、模型蒸馏和微调实验。
6. OPUS-MT / MarianMT:轻量、成熟、固定语言对仍然好用
OPUS-MT 来自 Helsinki-NLP/MarianMT 生态,是 Hugging Face 上最常见的开源翻译模型路线之一。它通常是按语言对或语言组发布的小模型,不像 TranslateGemma 或 MADLAD 那样追求一个模型覆盖大量语言。
特点:OPUS-MT 的优势是简单实用。你可以为固定语言对下载对应模型,在本地快速做批处理、脚本翻译、离线翻译。
优点:模型小、推理快、资源要求低、部署成熟。对一些固定语言对,如果你只是要“够用、便宜、可离线”,OPUS-MT 仍然是很好的起点。
缺点:质量上限有限,尤其在长句、专业术语、风格一致性、复杂格式文本方面不如新一代 LLM 翻译模型。多语言统一管理也更麻烦,因为你可能需要维护很多个语言对模型。
适合人群:个人开发者、离线工具开发者、小型内部系统、边缘设备和低成本部署场景。
应用场景:固定语言对批量翻译、CLI 工具、离线翻译、轻量 App、旧系统翻译能力补充。
7. SeamlessM4T v2:语音翻译和多模态通信优先选择
SeamlessM4T v2 是 Meta 的多语言多模态翻译模型,支持语音到语音、语音到文本、文本到语音、文本到文本和自动语音识别。Meta 官方材料称它面向接近 100 种语言的语音和文本翻译。
特点:SeamlessM4T 的核心不是“文本翻译质量榜第一”,而是“一个系统里打通语音和文本链路”。如果你的产品是会议翻译、直播翻译、语音助手、跨语言对话,它比纯文本模型更合适。
优点:任务覆盖广,能把 ASR、翻译、TTS 串成一个体系;对实时语音、跨语言沟通、可访问性场景很有价值。
缺点:部署复杂度明显高于纯文本模型。你需要考虑音频预处理、延迟、语音自然度、硬件成本、隐私合规和端到端错误累积。另外,SeamlessM4T v2 模型卡标注 CC-BY-NC-4.0,商业项目不能把它当作默认可商用模型。
适合人群:语音产品团队、会议工具、教育平台、可访问性应用、跨语言实时沟通产品。
应用场景:语音翻译、视频字幕、会议同传、语音客服、多语言语音助手。
8. IndicTrans2:印度语言项目的优先候选
IndicTrans2 来自 AI4Bharat,项目说明称其支持印度 22 个宪定语言,并覆盖多脚本低资源语言。Hugging Face 相关模型卡标注 MIT 许可,这对商业和研究项目都比较友好。
特点:IndicTrans2 是典型的区域语言专项模型。它不适合拿来做“全球所有语言”的默认模型,但如果你的目标是印度语言,它比泛用模型更值得优先测试。
优点:覆盖印度语言生态,包含低资源脚本处理经验,许可友好,研究和工程资料相对完整。
缺点:对非印度语言没有优势;工具链和语言代码处理需要认真阅读文档。社区也有人反馈使用时会遇到语言识别或调用方式上的困惑,说明上手成本不应被低估。
适合人群:印度市场 App、政府/教育/公益语言项目、印度本地化团队。
应用场景:英语到印度语言、印度语言互译、教育内容翻译、公共服务文本翻译。
9. CAT-Translate:日英双向翻译的专项小模型路线
CAT-Translate 是 CyberAgent 在 2026 年活跃更新的日英双向翻译模型系列,包含 0.8B、1.4B、3.3B、7B 等尺寸。其 7B 模型卡显示支持英语到日语、日语到英语翻译,并标注 MIT 许可。
特点:CAT-Translate 的价值在于“专”。它不试图覆盖所有语言,而是把日英这个高价值语言对做深。其论文场景也提到法律、医疗、金融、专利等需要隐私保护和有限 GPU 预算的场景。
优点:MIT 许可友好;尺寸梯度完整;适合本地部署;对日英专项翻译更聚焦。
缺点:语言覆盖非常窄。如果你的产品需要中文、韩文、欧洲语言或多语言统一模型,CAT-Translate 只能作为日英专线,而不是主模型。
适合人群:日英内容团队、日本市场产品、法务/专利/医疗文本团队、日英私有化翻译需求。
应用场景:日英文档翻译、日英字幕、漫画/轻小说初译、专利和合同预翻译、企业内部日英知识库。
10. PLaMo Translate:日本生态里的日英翻译强候选
PLaMo Translate 是 Preferred Networks 发布的翻译专用模型,面向日英翻译和本地执行场景。模型卡提醒用户这是新技术,输出可能出现不准确或偏差,并且使用前需要查看 PLaMo community license。
特点:PLaMo Translate 适合认真做日英翻译评测的团队。与 CAT-Translate 相比,它更像日本本土 LLM 生态的翻译专项路线。
优点:适合日英本地部署实验;日本语言生态相关资料较多;对日语场景有针对性。
缺点:许可不是简单的 Apache/MIT 路线,商业使用前需要确认;非日英场景价值有限;模型卡也明确提醒需要做风险评估。
适合人群:日本市场团队、日语内容平台、希望本地部署日英翻译的开发者。
应用场景:日英长文本、日语内容本地化、内部资料翻译、日英 benchmark 对比。
真实社区反馈:开发者最关心什么?
从 Google 前列结果和社区讨论来看,用户关心的问题并不是“哪个模型最炫”,而是四个很朴素的问题。
第一,商业许可到底能不能用。在 Reddit 和 Hugging Face 讨论里,NLLB 的 CC-BY-NC 许可经常被提到。很多人喜欢 NLLB 的覆盖能力,但只要进入商业产品,非商业许可就会变成硬门槛。相对来说,LMT-60、MADLAD-400、CAT-Translate、IndicTrans2 这类标注 Apache-2.0 或 MIT 的模型更容易进入商业评估流程。
第二,小模型能不能真的本地跑。OPUS-MT、CAT-Translate 小尺寸、Hy-MT2 1.8B 量化、TranslateGemma 4B,都是社区更愿意尝试的原因。对很多团队来说,能在一张消费级显卡、Apple Silicon 或私有服务器上稳定跑,比理论最佳质量更重要。
第三,泛用大模型不一定赢过翻译专用模型。社区里经常有人问“为什么不用普通多语言 LLM 直接 prompt 翻译?”答案是:可以,但当你需要格式保持、术语一致、批量稳定、固定语言对高质量输出时,翻译专用模型仍然有意义。
第四,真实语言混合场景很难。例如 Hy-MT2 的 Hugging Face 讨论里,有用户反馈 Hinglish 这类口语混合翻译不如预期。这类反馈提醒我们:benchmark 好不等于所有真实输入都好,尤其是混合语、俚语、行业黑话、OCR 噪声和字幕断句。
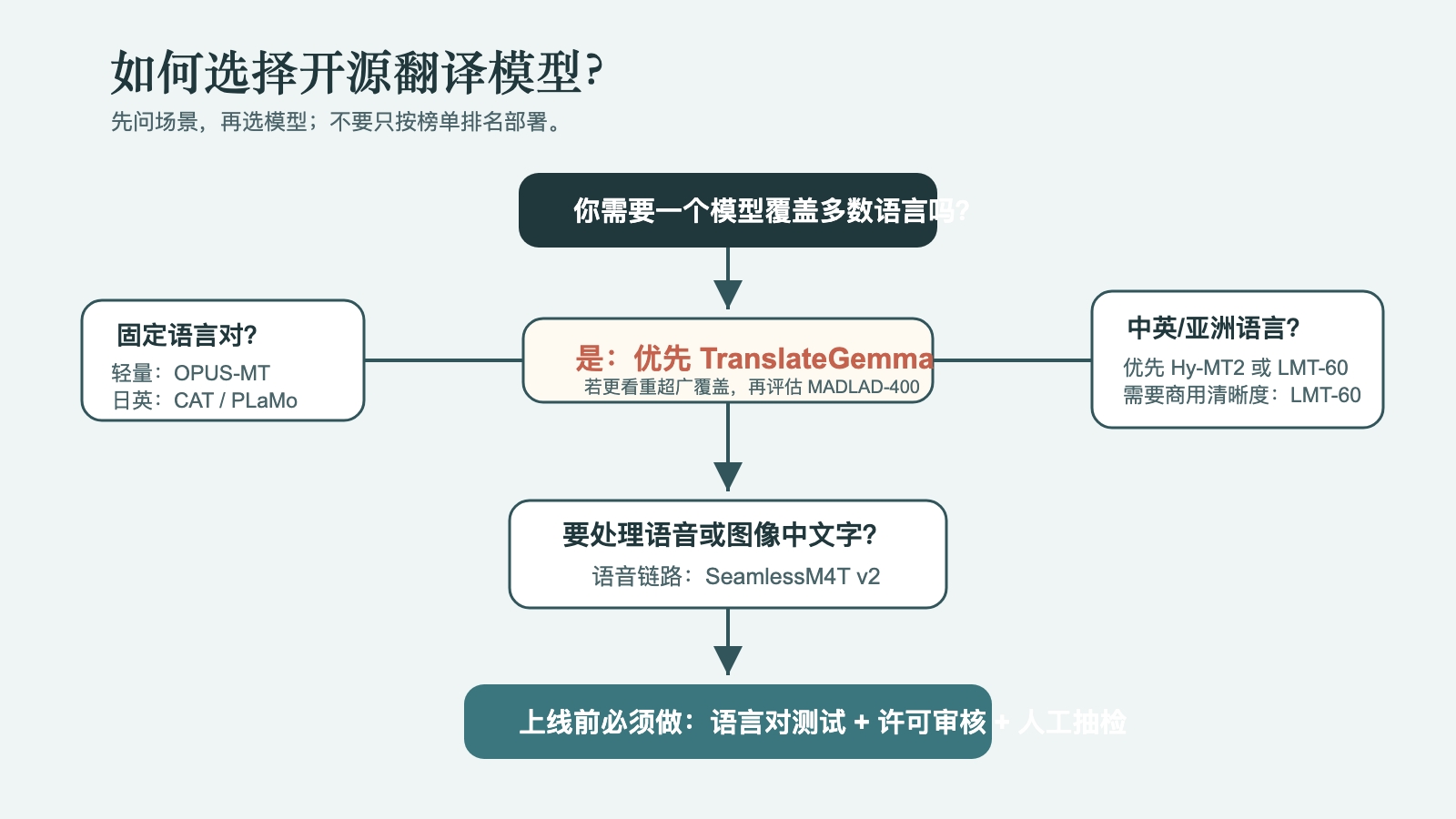
按场景选择:不要把“最佳”理解成唯一答案
如果你要做一个覆盖主流语言的产品默认翻译模型,先测 TranslateGemma 12B,然后用 LMT-60 或 MADLAD-400 做对照。TranslateGemma 更现代,LMT-60 对中文和 Apache-2.0 更友好,MADLAD-400 语言覆盖更广。
如果你主要做中英和亚洲语言,优先测 LMT-60 和 Hy-MT2。LMT-60 在许可上更简单,Hy-MT2 在复杂业务翻译和指令跟随上值得测,但要先审许可。
如果你做低资源语言研究,NLLB-200 仍然是重要基线。但如果要商业化,MADLAD-400 或其他许可更宽松模型可能更现实。
如果你做日英专项,优先测 CAT-Translate,再把 PLaMo Translate 作为强候选。专项模型往往比“万能模型”更适合高价值固定语言对。
如果你做印度语言,IndicTrans2 应该进入第一批测试名单。
如果你做语音翻译、会议翻译、视频字幕,SeamlessM4T v2 比纯文本模型更贴近系统需求。
如果你只需要离线、轻量、固定语言对,OPUS-MT 很可能仍然是最快上线的选择。
上线前的测试清单
在真正部署开源翻译模型前,建议至少准备 200-500 条真实样本,而不是只用公开 benchmark。样本应该包含短句、长句、专业术语、表格、Markdown、HTML、JSON、字幕、OCR 噪声、口语、客服对话和你最重要的语言对。
人工评测时,不要只问“通不通顺”。要问:原意是否保留?有没有漏译?术语是否一致?数字、货币、单位、日期是否正确?品牌名和人名是否被乱翻?格式是否保持?是否有幻觉式补充?是否适合目标市场文化?
工程评测时,要记录平均延迟、吞吐、显存、量化后质量损失、批处理速度、错误率、失败重试策略和日志脱敏方案。
法律评测时,要把模型许可、训练数据许可、商用限制、地域限制、再分发限制、模型输出使用政策一起检查。尤其是“开放权重”模型,不要默认等于可自由商用。
最终推荐
2026 年最佳开源翻译模型的推荐可以压缩成一句话:通用默认选 TranslateGemma,中文和商业许可优先选 LMT-60,复杂企业翻译评估 Hy-MT2,超广语言覆盖选 MADLAD-400,低资源研究看 NLLB-200,轻量固定语言对用 OPUS-MT,语音多模态选 SeamlessM4T,印度语言选 IndicTrans2,日英专项选 CAT-Translate 或 PLaMo。
如果你是第一次做开源翻译模型选型,建议不要一次性比较 20 个模型。更好的路线是:先选 3 个候选模型,用你的真实文本测试一周。比如通用产品可以测试 TranslateGemma、LMT-60、MADLAD-400;中文业务可以测试 LMT-60、Hy-MT2、TranslateGemma;日英业务可以测试 CAT-Translate、PLaMo、TranslateGemma;语音业务可以测试 SeamlessM4T,再搭配一个纯文本模型做 fallback。
FAQ
2026 年最值得优先测试的开源翻译模型是哪一个?
如果只选一个通用候选,建议先测试 TranslateGemma,尤其是 12B 或 27B 版本。它是 2026 年发布的新一代开放翻译模型,覆盖 55 种语言,并且具备图像中文字翻译潜力。但如果中文和商业许可更重要,NiuTrans LMT-60 可能是更实际的第一选择。
开源翻译模型可以直接用于商业产品吗?
不一定。Apache-2.0、MIT 通常更适合商业使用,但 NLLB-200 的 CC-BY-NC 属于非商业许可,TranslateGemma、Hy-MT2、PLaMo 等模型也需要阅读各自许可条款。上线前应由法律或合规人员确认。
NLLB-200 现在还值得用吗?
值得,但主要适合研究、非商业、低资源语言和基线评测。对商业产品来说,NLLB-200 的非商业许可会成为主要障碍。
MADLAD-400 和 TranslateGemma 怎么选?
如果你需要更广语言覆盖和许可友好度,优先测 MADLAD-400;如果你需要更现代的通用翻译体验、更好的模型生态和图像文字翻译能力,优先测 TranslateGemma。
中文翻译应该选哪个开源模型?
优先测试 NiuTrans LMT-60 和 Tencent Hy-MT2 / Hunyuan-MT,再用 TranslateGemma 做对照。LMT-60 的 Apache-2.0 许可对商业团队更友好,Hy-MT2 则更强调复杂业务翻译和指令跟随。
手机端或本地轻量部署用什么模型?
固定语言对可以从 OPUS-MT 开始;如果需要更现代的翻译能力,可以测试 TranslateGemma 4B、Hy-MT2 1.8B 量化版本或 CAT-Translate 小尺寸模型。最终选择取决于设备内存、延迟要求和语言对。
日英翻译选 CAT-Translate 还是 PLaMo?
如果你重视 MIT 许可和多尺寸小模型,优先测 CAT-Translate;如果你在日本生态内、愿意处理 PLaMo community license,并希望比较日英专项质量,可以把 PLaMo Translate 纳入测试。
开源翻译模型会比 DeepL 或 Google Translate 更好吗?
不一定。开源模型的优势是可私有化、可控、可微调、可离线和成本可预测;商业 API 的优势通常是稳定、易用和质量均衡。实际项目中,最好用真实业务样本做人工评测,而不是只看模型名。